The email list is the lifeblood of marketing efforts for many, many online businesses. For mine, it is no different. Using email considerably increases both the engagement of my audience and the number of sales I make and as a result, I really care about the quality of my subscriber data.
Most people use tags as a primary tool for organizing subscribers, just as most email software encourages them to.
I hope to make a strong case that this is a mistake in most cases.
# Why email?
For now at least, email is one of the few major decentralized online communication channels remaining. People who choose to subscribe to your email list will generally see your emails appear in their inboxes.
A decade ago the same was essentially true on RSS feeds, Facebook, YouTube and Twitter. People's feeds were exactly the things (or people or channels) they'd choses to follow, in chronological order. No longer.
Today, feeds are ordered however the massive tech company that runs them wants them to be. Generally that means showing more ads and more content that will keep you on the platform as long as possible to view those ads.
Email, however, is an open protocol that no single company owns. As a result, it's not up to Facebook or Google (yet, at least) to order your inbox in order to maximize their ad revenue. Even if they did, customers could choose a different provider. This makes email a uniquely powerful marketing channel.
(RSS remains as open as ever, but few people use it for text. Podcasts share many of email's attractive properties, though.)
# How tags are used
Most email service providers allow a way to tag customers and make it a primary way of organizing your subscibers. A subscriber can be tagged with many different tags and a tag can be used on many subscribers.
Initially tags appear to be a very flexible tool that can be used to encode just about anything you want to about a customer that would affect which emails you send them.
For example, an ecommerce site might tag a subscriber with Austin, TX if the customer lives in Austin. Or they might tag a customer as high value if they make a purchase over X number of dollars.
A programming screencast membership site, such as the one I run, might tag subscribers with things like monthly_member, intermediate learner, freelancer or learning Absinthe GraphQL.
# The problem
So far, everything seems reasonable. But what happens when members change plans, cancel, pause or resubscribe? Then we'll have tags like yearly_member, cancelled, paused, etc.
Looking back at subscriber data months later, and writing a new email aimed at a given segment, what do I do if I see a subscriber tagged both monthly_member and cancelled? Not knowing which tag was applied first, it's not clear what the status of the member is.
Of course, one fix would be to encode rules such that anytime one tag were applied all conflicting tags were removed. E.g. applying the yearly_member tag would remove the monthly_member, paused, cancelled and all other membership-related tags. This isn't a great solution, though.
For one it's extremely likely that sooner or later someone using the system would be unclear about which tags are incompatible. In fact, I've never yet encountered a large tag-driven email marketing effort using tags as a that doesn't have issues with incorrect or unreliable subscriber data.
Another problem is that even if you perfectly orchestrate a system of untagging conflicting tags each time a new tag is applied, you'll be doing the equivalent of making a crazy spreadsheet like this:
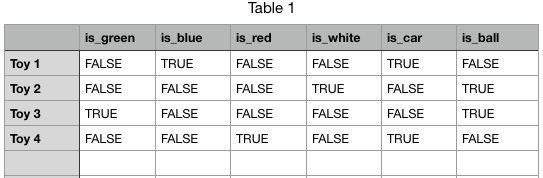
# How I use tags safely
Having seen a tagging mess a few times and then reading some of Brennan Dunn's clearly articulated descriptions of the same problem, I've adopted some practices that have helped me greatly.
Though tags are technically a many-to-many relationship, I treat them as a boolean from the perspective of a given subscriber either having or not having a characteristic.
As a result, I work very hard to only use tags for boolean characteristics that will not change. For example, is_member is a poor choice of a tag (for the reasons in the previous section), but has_purchased_membership is okay since it will never become false in the future. Here are other tags that I use:
has visited sales pagehas read XYZ posthas been pitchedhas completed intro course
As a rule of thumb, if it's in the present perfect or past perfect tense, it's a safe tag to use.
# Custom fields for everything else
The solution is to use key-value pairs instead of boolean tags. On the email service provider I use, Convert Kit, this is called "custom fields".
Instead of is_beginner, is_intermediate and is_advanced tags, I have a custom field "elixir_experience" which I set to "beginner", "intermediate" or "advanced" on my subscribers who identify their level. Similarly, I have custom fields for their ID on my server, the topic they most want to learn from me, etc, etc.
Custom fields certainly aren't as prominent in CK's documentation and they're not tied into quite as many automation features as tags are, but it's worth it to have clean, reliable subscriber data that doesn't rely on a brittle system of removing conflicting tags when a new one is applied.
If it were the spreadsheet containing the same data as the crazy one a page above, it would look like this:
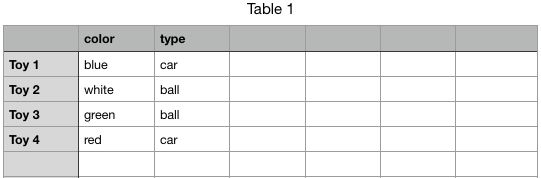
# Final thoughts
Email service providers aren't generally aimed at devs, so it's a bit disguised that their customer segmentation features are essentially a spreadsheet hiding behind a GUI. But that's what they are. And a spreadsheet is equivalent to a relational database.
If you're a programmer, you can apply the same lessons you've learned designing your schemas to your email automations.